![]() 2021.12.21
2021.12.21
![]() 2022.02.02
2022.02.02
![]() Fabeee社員ブログ
Fabeee社員ブログ

Pythonでデータ分析を始めてみようとしたけれど情報が多くて、なにから始めたらいいのかちょっとわかりにくいですよね。
この記事では、
- なぜPythonでデータ分析をするのか
- Pythonでデータ分析する際の流れ
- Pythonでデータ分析する際によく使うライブラリと使い方の例
について説明します。
筆者は現在まさにPythonを主に用いてデータ分析をしている現役のデータサイエンティストですので、それなりの信憑性はあるかと思います。
簡単にではありますがPythonのコードも載せておりますので、ぜひ学習の参考にしてください。
目次
Pythonでデータ分析をするメリット
データ分析ができるツールはたくさんあります。有名なツールとしてはExcelやR, SAS, SPSS等があります。
では、ツールはたくさんあるのに、なぜPythonが選ばれることが多いのでしょうか?
この章では多くのデータ分析ツールがある中で、なぜPythonが選ばれるのかについて説明していきます。
Pythonにはデータ分析や機械学習に便利なツールが豊富にある
Pythonにはデータ分析をする上で便利なツールが豊富にあります。
詳しくは後述しますが、線形代数関連の演算に便利なNumpyやデータベース操作が可能なPandasなどが簡単に導入できます。
またPythonでデータ分析する方は世界中にも多くいるため情報が多く、プログラミング等で困ったときにGoogle検索するときなど目的の情報にアクセスしやすいといった利点もあります。
Pythonにはスクレイピングやクローリングなどデータ収集に便利なツールが豊富にある
データ分析をしていると、「このWebサイトのデータがほしい」と思うことがよくあります。
しかし、自社で開発しているWebサイトでもない限り、直接データベースを見に行くことはできません。
このような際によく使われるのがスクレイピングやクローリングといった技術です。
スクレイピングとクローリングについてはここでは詳しく説明しませんが、これらを用いると任意のWebサイトから自動でデータを収集することができます。
これらの技術を使うにはツールが必要となりますが、それらはすでにPythonではBeautiful SoupやScrapyという名前で公開されており、簡単に導入できます。
Beautiful Soup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Scrapy: https://scrapy.org/
PythonはWeb開発やマイコンソフトウェア開発もできる
Pythonはデータ分析以外にも、Web開発やマイコンのソフトウェア開発にもよく用いられるプログラミング言語です。
これによって、例えばデータ分析用のWebサイトを作りたいときにもWeb開発とデータ分析で同じ言語を使うことができ、開発の負担を減らせるなどのメリットがあります。
PythonでWeb開発をする際はDjangoやFast APIというライブラリが有名です。
Pythonでマイコンのソフトウェア開発する際はRaspberry Piというマイコンがよく用いられます。
Django: https://www.djangoproject.com/
Fast API: https://fastapi.tiangolo.com/
Raspberry Pi: https://www.raspberrypi.org/
Pythonでデータ分析する際の流れ
データ分析をする際にいくら便利なPythonを使っても、やはりそもそものデータ分析の知識は必要となってきます。
この章では基本的なデータ分析の流れと、それをシステムに組み込むところまでの流れを簡単に説明します。具体的なPythonのライブラリ名は次の章で紹介します。
データ分析をする目的を明確にする
データ分析をする際にまずやることは、データ分析目的の明確化です。
ここを決めずにデータ分析を始めてもなにも示唆に富む結果は得られません。
目的を明確にするだけでなく、仮説も立てられるとより良いです。
目的と仮説とは、例えば売上が減っているのであれば、目的は「売上が減っている原因を特定する」となり、それに対する仮説は「20代男性からの売上が減っているのではないか?」という具合です。
この仮説に対して数字と論理を用いて検証するのがデータ分析です。
データを収集する
仮説が立てられたら、いよいよデータを扱っていきます。
しかし、いきなりデータを扱いところではありますが、まずはデータを収集するところからする必要があるのが実際のデータ分析業務です。
データの収集とは自社で運用しているWebサイトがあればそこのデータベースを参照するかもしれませんし、各国の政府が公開しているデータや、その他の外部データを用いることになるかもしれません。
前述のスクレイピングやクローリングの技術を用いてWebサイトからデータ収集を行うことになるかもしれません。
クライアントワークをしているのであれば、クライアントと直接連絡を取り、データをもらうことはできるか交渉するところから始めることもあります。
データを加工する
データを収集できても、それがそのまま分析に使えるデータとは限りません。
無駄なデータが入っていたら削除する必要がありますし、日付データなのに特殊なデータ型で入っていたら列ごとに処理を行う必要があるかもしれません。
このようなデータ分析の前に行うデータ整形処理のことを一般に “前処理” と言います。
この前処理が少々骨の折れるで作業ではあるのですが、ここがしっかりしていないと後のデータ分析でいい結果がでないので、ここはデータ分析者の腕の見せどころの一つと言えるでしょう。
データ分析や機械学習の分野に “Garbage in, garbage out(ゴミを入れたら、ゴミが出てくる)” という格言があります。
これは要は「前処理をきちんとしないと、精度のいいデータ分析や機械学習モデル構築はできない」という意味です。
他にも “データ分析は前処理が8割” という言葉もあり、それほど前処理は重要かつ時間のかかる作業ということがおわかりいただけるかと思います。
データを分析する
データの前処理ができたら、いよいよデータ分析です。
データ分析と一言に言っても様々な手法がありますし、ゴールも多種多様です。
手段もゴールも多様な中で、共通している作業がいくつかあります。
その代表的なものとして、データの可視化が挙げられます。
データの可視化とは文字通りデータを可視化することですが、これが分析の際には非常に重要です。
基本的な統計量の平均値や分散が同じでも、散布図を書いてみたら全然違う形をしていることがあるかもしれません。
統計量等の数字だけでデータを解釈するのではなく、データを可視化して視覚的にもデータを解釈することが重要です。
可視化の重要性をよく示すものとして、 “アンスコムの例” があります。
アンスコムの例
アンスコムの例とは以下の図で示されるものです。
以下の4つのグラフはそれぞれ、
- x の平均
- x の標本分散
- y の平均
- y の標本分散
- x と y の相関係数
- 回帰直線
がほぼ一致しています。
上記の各統計量がほぼ一致しているのにも関わらず、グラフの形は明らかに異なっています。
統計量のみでデータを解釈しようとすると解釈を誤ることがあるので、しっかりと可視化をして多角的にデータを見る必要があります。
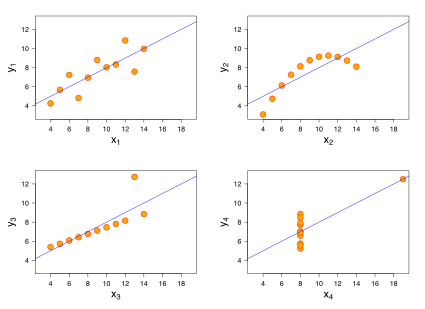
( https://ja.wikipedia.org/wiki/アンスコムの例 より引用 )
(データ分析の結果をまとめる)
社内の業務であればデータを分析して終わりということもあるかもしれませんが、クライアントワークとなると分析以降の作業もいくつかあります。
これ以降ではデータ分析そのものとは少しずれますが、データ分析業務で実際によく行うことについて簡単に説明していきます。
クライアントワークのデータ分析業務でほぼ絶対にあるのが、プレゼンです。
データ分析の精度ももちろん大事ですが、それをクライアントに適切に伝えるスキルも同様に大事です。
様々な種類のグラフを用意して視覚的にわかりやすい資料を作ったり、分析アルゴリズムの説明をすることもあるかもしれません。
クライアントに適切にデータ分析の結果を伝えるのがこの項目の目的です。
(機械学習のモデルの作成)
データ分析をして過去の傾向を把握し、「ではこの傾向が続くとしたら、未来はどうなるだろう?」というアウトプットを出すのが機械学習です。
機械学習はデータ分析と重なる領域も多く、機械学習モデルの構築も要件に入っていることもあります。
(Webアプリケーションへの組み込み)
機械学習モデルをクライアントに渡しても、それ自体はただのPythonのコードなのですぐに使えるものではありません。
そのため、機械学習モデル構築と同時にWebアプリケーションを構築することもよくあります。
その際はデータ分析者だけではスキルセットの不足等の理由で納品までが困難となることもあるため、Webサイト構築チームと組むこともあります。
Pythonでデータ分析する際によく使うライブラリ
Pythonにはデータ分析をする際に便利なライブラリが豊富に用意されています。
この章ではPythonデータ分析の際によく使うライブラリを紹介していきます。
Jupyter, Google Colaboratory
( https://jupyter.org/ より引用 )
JupyterはPythonの実行環境のようなものです。
一般的なエディタを用いてデータ分析することも可能ですが、Jupyterも用いることで一行一行コードが実行できたり、Markdownが書けたりと、そのまま説明資料にもできる非常に便利なツールです。
類似ツールとしてGoogle Colaboratoryがあります。
Google ColaboratoryはほとんどJupyterと同じで、サーバがGoogleのサーバを用いる点で異なっています。
Google Colaboratoryを用いる際は自身のコンピュータにPython環境を用意する必要は一切なく、ブラウザ上ですぐにPythonでデータ分析を始めることができます。
Jupyter: https://jupyter.org/
Google Colaboratory: https://research.google.com/colaboratory/
Numpy
Numpyは線形代数関連の演算をするのに便利なツールです。実装としてはPython標準モジュールののlistとよく似ています。
Numpyではベクトルや行列、テンソルの演算を簡単に実行することができ、Pythonでデータ分析をする際にはほぼ必須と言ってもいいほどよく使われています。
Numpy: https://numpy.org/
# ここでは具体例としてNumpyを用いて行列Aの逆行列を計算します。
# Numpyは慣習的にnpとして呼び出します。
import numpy as np
# 行列Aを定義します。
A = np.array(
[[1, 2],
[3, 4]]
)
# 行列Aの逆行列を計算します。
np.linalg.inv(A)
# 上記を実行すると以下が返ってきます。問題なく逆行列が計算できています。
# array([[-2. , 1. ],
# [ 1.5, -0.5]])Pandas
Pandasはデータベース操作をするのに便利なツールです。
データベースでよく用いられるのはSQLですが、Pandasはそれに似た作業をPythonのコードで扱うことができます。
データベース操作の他にも、後述するmatplotlibやseaborn等の可視化ツールと組み合わせることで、容易に複雑なグラフを表示などすることも可能です。
PandasもNumpyと同様に、Pythonでデータ分析する際はほぼ必須のツールです。
Pandas: https://pandas.pydata.org/
# ここでは具体例としてPnadasを用いて値段の平均を計算します。
# Pandasは慣習的にpdとして呼び出します。
import pandas as pd # PandasでDataFrame(データベースのようなもの)を定義します。
df = pd.DataFrame({'値段': [1000, 2300, 2600]}, index=['A社', 'B社', 'C社'])
# 平均を計算します。
df['値段'].mean()
# 上記を実行すると以下が返ってきます。問題なく値段の平均が計算できています。
# 1966.6666666666667matplotlib, seaborn, plotly
matplotlibはデータ可視化の際に便利なツールです。
散布図や棒グラフなどの基本的なグラフはもちろん、箱ひげ図やヒートマップなどのデータ分析の際によく使うグラフも豊富にあります。
matplotlibをベースにした可視化ツールとして、seabornもあります。
また動的にデータを可視化する際に便利なものとして、plotlyもあります。
これらのツールもNumpyやPandasと同様、Pythonでデータ分析する際はほぼ必須のツールです。
matplotlib: https://matplotlib.org/
seaborn: https://seaborn.pydata.org/
plotly: https://plotly.com/
# ここでは具体例としてmatplotlibを用いてサインカーブをプロットします。
# matplotlibは慣習的にpltとして呼び出します。
from matplotlib import pyplot as plt
# Numpyを用いてx, yを定義します。
x = np.linspace(-2*np.pi, 2*np.pi)
y = np.sin(x)
# matplotlibを用いて上記x, yを出力します。 plt.plot(x, y)
scipy
scipyは数値計算に便利なツールです。
scipyを用いると微積分や統計学関連の計算が簡単に実行できます。
ある程度複雑なデータ分析や統計学の仮説検定を用いる際によく用いられます。
scipy: https://scipy.org/
# ここでは具体例としてscipyを用いてe^xの0から5の範囲の面積を計算します。
# scipyから積分の関数をimportします。
from scipy.integrate import quad import numpy as np
# 関数e^xを定義します。
def f(x):
return np.e**x
# scipyを用いて計算します。
result, _ = quad(f, 0, 5) result
# 上記を実行すると以下が返ってきます。問題なく面積が計算できています。
# 147.41315910257657scikit-learn
scikit-learnは機械学習モデル構築に便利なツールです。
単回帰分析のような古典的なモデルはもちろん、ランダムフォレストやKMeans法のような教師なし学習のクラスタリングなどを容易に実装することができます。
また、機械学習モデル構築の際によく使う教師データと回答データの分割や正規化といった機械学習の前処理に便利な関数も豊富に用意されています。
scikit-learn: https://scikit-learn.org/
# ここでは具体例としてscikit-learnを用いて単回帰分析をします。
# scikit-learnから単回帰分析モデルをimportします。
from sklearn.linear_model import LinearRegression
# xとyを定義します。ここでは y=2x にノイズに加えたものを定義します。
x = np.linspace(-3, 3, 10) y = 2 * x + np.random.randn(len(x))*0.3
# モデルにscikit-learnのLinearRegressionを用いることを宣言し、fitメソッドで単回帰式を計算します。
model = LinearRegression() model.fit(x.reshape(-1, 1), y)
# 傾きと切片を出力します。
model.coef_, model.intercept_
# 上記を実行すると以下が返ってきます。
# (array([2.04356137]), 0.027139647024839956)
# これは要は y~2.04x+0.02 を意味しており、元の関数とよく似ており、問題なく計算できています。まとめ Pythonでデータ分析をするには?
この記事では、
- なぜPythonでデータ分析をするのか
- Pythonでデータ分析する際の流れ
- Pythonでデータ分析する際によく使うライブラリ
について説明いたしました。
この記事を参考にしていただき、ぜひPythonデータ分析の一歩目を踏み出してみてください!




