![]() 2020.03.05
2020.03.05
![]() 2021.08.12
2021.08.12
![]() Fabeee社員ブログ
Fabeee社員ブログ

はじめに
こんにちは。fabeeeの覆面エンジニアことマスクド・エンジニアです。そのままですね。。
長いのでマスクマンとお呼びください。
業務では主にjavaの開発案件に携わっておりますが、最近は弊社推しの言語であるpythonの勉強をしています。
そこで、今回のテーマはpythonでやってみたシリーズの第二弾ということで、『pythonで本を読んでみた』です。
ちなみに第一弾をお読みでない方はこちらをご覧ください。
今回読んでいく作品は、旧千円札で有名な明治の文豪、夏目漱石の『夢十夜』にしたいと思います。
余談ですが、わたくし大学時代は日本語日本文学科(通称:日文)の卒業生でして、専攻は近代文学でした。卒業論文のテーマで『夢十夜』を選択しようとしていたら、同期に先を越されてしまい、泣く泣く二葉亭四迷にしたというほろ苦い過去があります。二葉亭四迷に失礼な話ですね。すみません。
ちなみに愛子さまも日文に進学されるそうですが、今後日文ブームが巻き起こるのでしょうか。
『夢十夜』を読む

さて、本題に戻りまして、早速『夢十夜』を読んでいきましょう。
そもそも『夢十夜』とは、「こんな夢をみた」から始まる幻想的な十の夢のお話で、タイトルの通り第一夜~第十夜までの十部構成になっています。自然主義作家として人間のリアルな内面を描くことが多かった漱石としては異色な幻想文学テイストな作品ですが、個人的にとても好きな作品です。これまで様々な読み方や解釈がなされてきましたが、pythonで読まれるのはこれが初めてなのではないでしょうか。
今回は以下の方法で『夢十夜』を読んでみたいと思います。
・Janomeを利用して形態素解析にかける
・感情極性対応表を利用し、感情分析を行う
それではやっていきましょう。
『夢十夜』は青空文庫からダウンロードしてきたものを、一夜ごとに分割して、作品のメタ情報など不要な部分を取り除いております。
まずは、<第一夜>部分を形態素解析し、頻出単語を見てみましょう。
import codecs
from janome.tokenizer import Tokenizer
# テキスト読み込む
with codecs.open("yume_1.txt", "r", "utf-8") as file:
yume1 = file.readlines()
# 形態素解析オブジェクトの生成
tn = Tokenizer()
# テキストを一行ずつ処理
word_dic = {}
for line in yume1:
for w in tn.tokenize(line):
word = w.surface
ps = w.part_of_speech
# 名詞だけカウントする
if ps.find('名詞') < 0:
continue
if not word in word_dic:
word_dic[word] = 0
word_dic[word] += 1
# 頻出単語を表示
keys = sorted(word_dic.items(), key=lambda x:x[1], reverse=True)
for word, cnt in keys[:10]:
print("{0}({1})\n".format(word, cnt), end="")
<第一夜>で頻出している単語の上位10はこんな感じでした。()内は出現回数です。
自分(19)
女(12)
上(7)
日(7)
百(7)
静か(5)
の(5)
眼(5)
ん(5)
年(5)
第一夜は、死んだ「女」を「自分」が百年待ち続け、百合の花として生まれ変わった「女」と再会するという話でしたね。
やはり、「自分」、「女」、「百」という言葉が多く使われているようです。
次は感情極性対応表を利用し、感情分析をして、良い夢なのか悪夢なのか判定していきたいと思います。
感情極性とは、ある言葉が持つ印象の良し悪しを分類したものです。その印象を数値化して言葉に割り当てたものが感情極性対応表です。例えば、「優れる」という単語には1、反対に「死ぬ」という単語には-0.999999というふうに、ポジティブなイメージのものは1に近く、ネガティブなイメージのものは-1に近くなるように数値が割り当てられています。
今回は東工大の奥村・高村研究室から提供されているものを利用します。(こちらからダウンロードできます。)
形態素解析した第一夜の単語をそれぞれ感情極性対応表の数値に置き換え、第一夜全体の数値の平均値が1に近ければ、良い夢、-1に近ければ悪夢と判定しましょう。
# 辞書を作成
def load_pn_dict():
dic = {}
with codecs.open('pn_ja.dic', 'r', 'shift_jis') as file:
dict = file.readlines()
for line in dict:
columns = line.split(':')
dic[columns[0]] = float(columns[3])
return dic
pn_dic = load_pn_dict()
PNlist = []
for line in yume1:
for w in tn.tokenize(line):
# 辞書にヒットさせるために単語を基本形にする
bf = w.base_form
if bf in pn_dic:
PNlist.append(pn_dic[bf])
else:
PNlist.append(0)
print("第一夜:{:.3f}".format(sum(PNlist)/len(PNlist)))
結果は、、、-0,224
やや悪夢なようですね。。。
ちなみに第一夜~第十夜までの結果は以下のようになりました。
第一夜:-0.224
第二夜:-0.201
第三夜:-0.199
第四夜:-0.182
第五夜:-0.234
第六夜:-0.163
第七夜:-0.202
第八夜:-0.219
第九夜:-0.227
第十夜:-0.207
折れ線グラフにしてみました。
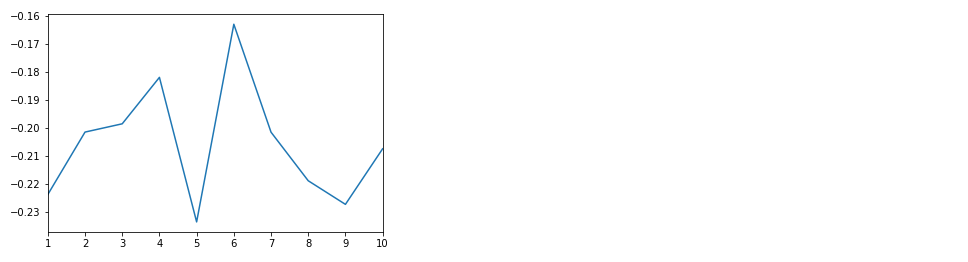
こうしてみるとネガティブな夢しかありませんね。。。
第一夜は結末的にはハッピーエンドとも取れますが、今回の感情分析ではネガティブな判定となっております。
作品全体を通して「女」、「死」といった語句がよく使われており、この「女」という語は対応表では-0.173387とネガティブなワードとして分類されているようですので、そのあたりが原因でしょうか。また、対応表自体がポジティブな語に対してネガティブな語の方が10倍多く含まれているみたいで、文全体で見るとどうしてもネガティブな単語に引きずられがちな判定になってしまうようです。
特に最もネガティブ値が高い第五夜では「女」、「死」といった語が多く含まれています。
(実際に第五夜はバッドエンドですので、こちらに関してはあながち間違いではないかもしれませんね。)
このあたりのことを踏まえて、もっと正確に読み解くためには、まだまだ改善の余地がありそうですね。
さいごに
いかがだったでしょうか?
pythonで『夢十夜』を読んできましたが、、、やはり名作でしたね。
作品に興味を持たれた方はぜひ一度pythonではなく直に読んでみてください。
私の学部生時代を思い返してみると、当時の私含め、日文はとかくアナログな学生が多い印象の学部でしたが、pythonを学習していて、ふと「文学研究に活かせないのだろうか?」という疑問が湧いたのが今回のブログテーマのきっかけでした。
今後は、テクノロジーを活用しての文学研究なんてことをする学生も出てくるのでしょうか。
ここまでお付き合いくださりありがとうございました。
またお会いしましょう。
AIコンサル/SES/受託開発のご依頼についてはこちら




